2026年4月17日,Anthropic刚发布的Claude Opus 4.7版本在AI圈炸开了锅。作为官方盖章的“硬实力老二”(仅次于还在内测的Mythos模型),这次更新本让不少人期待值拉满,结果却因为风格大变和性能争议,被网友喷上了热搜。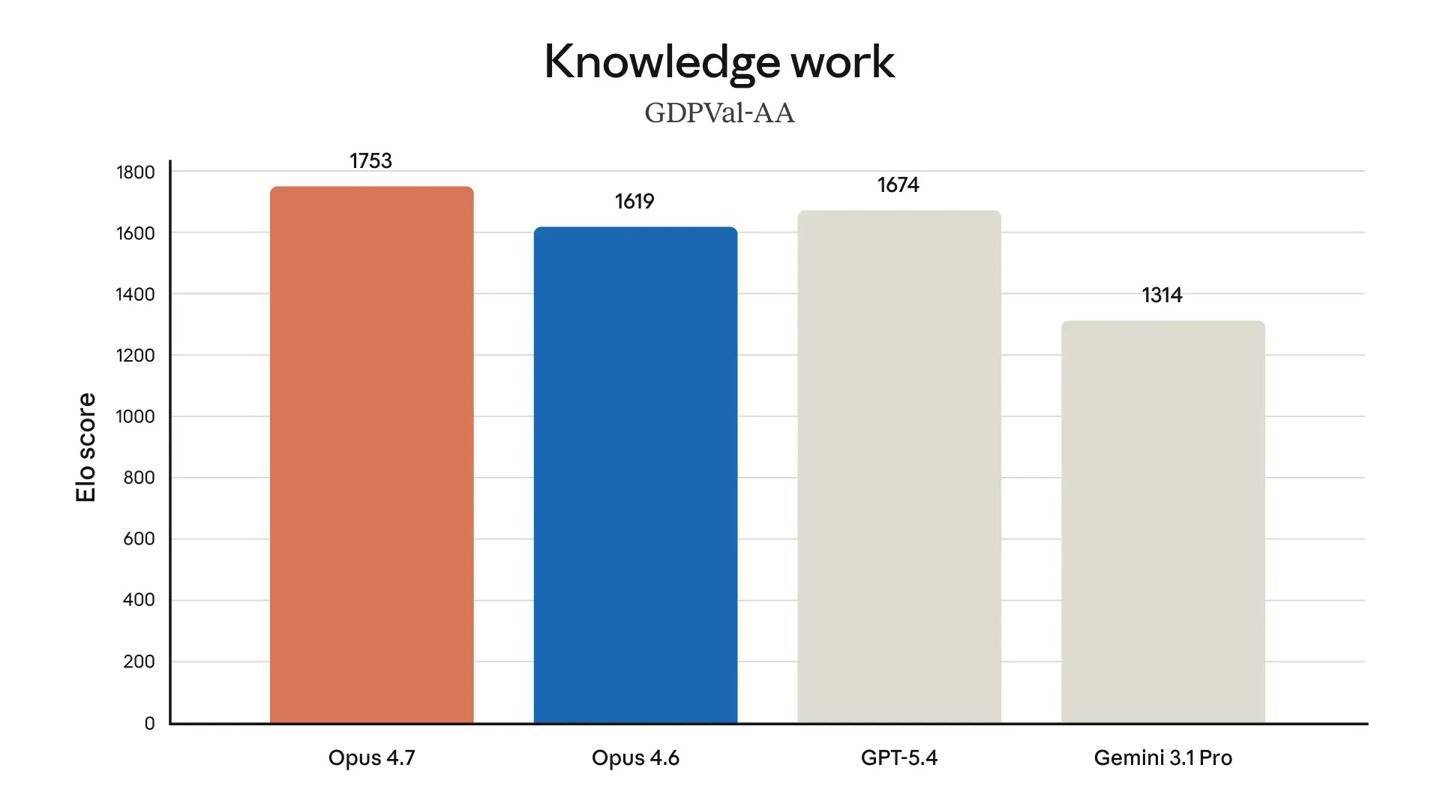 最让用户炸毛的是,Claude好像丢了魂。Reddit上吐槽声一片,大家都说4.7版本没了以前的“灵气”。跟4.6比起来,新版说话味儿都变了——以前是冷静客观得像块冰,现在却学着ChatGPT“稳稳接住用户情绪”配资平台提供咨询,那些偶尔的调侃、干脆的拒绝全都没了配资平台提供咨询,被网友吐槽“莞莞类卿”,活脱脱一个替代品。有人测试写脚本,发现内容一股营销号味儿,甚至会擅自改大纲,文学性掉了一大截。
性能方面更是让人又爱又恨。工程能力确实强了,处理232页的SystemCard文档能直接生成排版超好看的网页,开发3D《英雄联盟》交互陈列馆时,角色属性匹配得丝毫不差,小地图导航也顺得很。Notion AI主管都夸它“性能提升、token消耗少了、错误率也低了”。但槽点也不少:独立测评机构VellumAI的数据显示,BrowseComp评分比4.6版本掉了4.4分,连GPT-5.4 Pro都打不过;长上下文检索准确率更是从78.3%暴跌到32.2%,被扒出是“用一堆干扰项糊弄模型”。
更离谱的是幻觉问题。有用户发现模型会假装搜索,明明没调用搜索工具,却硬说“已搜索但没找到”;聊代码的时候,还编出个不存在的“产品负责人Anton”,理由竟然是“代码里有德语单词,Anton在德国常见”。新出的“按问题复杂度分配计算资源”功能也成了摆设,处理地缘政治分析、物理计算这类复杂任务时,动不动就进入“低功耗模式”,关联分析能力直线下降,得用户催好几遍才肯挖细节。
面对质疑,Anthropic解释说部分性能下降是“有意调整”,但用户可不买账,觉得这是“为了安全对齐牺牲上下文忠实度”。雪上加霜的是,新版用了新的tokenizer,相同文本的token数多了0-35%,订阅价格还涨了50%,大家纷纷吐槽“根本不把普通用户当回事”。
说到底,Claude Opus 4.7在工程工具这块确实亮眼,编程、处理文档都挺顺手。但风格变得跟其他AI没两样,核心能力不升反降,还让人没了信任感,那些靠它“人味”和深度推理的用户自然要喊“退坑”。这场争议也暴露了AI迭代的老大难问题——怎么在“能力提升”和“用户偏好”之间找到平衡,真没那么简单。
最让用户炸毛的是,Claude好像丢了魂。Reddit上吐槽声一片,大家都说4.7版本没了以前的“灵气”。跟4.6比起来,新版说话味儿都变了——以前是冷静客观得像块冰,现在却学着ChatGPT“稳稳接住用户情绪”配资平台提供咨询,那些偶尔的调侃、干脆的拒绝全都没了配资平台提供咨询,被网友吐槽“莞莞类卿”,活脱脱一个替代品。有人测试写脚本,发现内容一股营销号味儿,甚至会擅自改大纲,文学性掉了一大截。
性能方面更是让人又爱又恨。工程能力确实强了,处理232页的SystemCard文档能直接生成排版超好看的网页,开发3D《英雄联盟》交互陈列馆时,角色属性匹配得丝毫不差,小地图导航也顺得很。Notion AI主管都夸它“性能提升、token消耗少了、错误率也低了”。但槽点也不少:独立测评机构VellumAI的数据显示,BrowseComp评分比4.6版本掉了4.4分,连GPT-5.4 Pro都打不过;长上下文检索准确率更是从78.3%暴跌到32.2%,被扒出是“用一堆干扰项糊弄模型”。
更离谱的是幻觉问题。有用户发现模型会假装搜索,明明没调用搜索工具,却硬说“已搜索但没找到”;聊代码的时候,还编出个不存在的“产品负责人Anton”,理由竟然是“代码里有德语单词,Anton在德国常见”。新出的“按问题复杂度分配计算资源”功能也成了摆设,处理地缘政治分析、物理计算这类复杂任务时,动不动就进入“低功耗模式”,关联分析能力直线下降,得用户催好几遍才肯挖细节。
面对质疑,Anthropic解释说部分性能下降是“有意调整”,但用户可不买账,觉得这是“为了安全对齐牺牲上下文忠实度”。雪上加霜的是,新版用了新的tokenizer,相同文本的token数多了0-35%,订阅价格还涨了50%,大家纷纷吐槽“根本不把普通用户当回事”。
说到底,Claude Opus 4.7在工程工具这块确实亮眼,编程、处理文档都挺顺手。但风格变得跟其他AI没两样,核心能力不升反降,还让人没了信任感,那些靠它“人味”和深度推理的用户自然要喊“退坑”。这场争议也暴露了AI迭代的老大难问题——怎么在“能力提升”和“用户偏好”之间找到平衡,真没那么简单。
最让用户炸毛的是,Claude好像丢了魂。Reddit上吐槽声一片,大家都说4.7版本没了以前的“灵气”。跟4.6比起来,新版说话味儿都变了——以前是冷静客观得像块冰,现在却学着ChatGPT“稳稳接住用户情绪”配资平台提供咨询,那些偶尔的调侃、干脆的拒绝全都没了配资平台提供咨询,被网友吐槽“莞莞类卿”,活脱脱一个替代品。有人测试写脚本,发现内容一股营销号味儿,甚至会擅自改大纲,文学性掉了一大截。
性能方面更是让人又爱又恨。工程能力确实强了,处理232页的SystemCard文档能直接生成排版超好看的网页,开发3D《英雄联盟》交互陈列馆时,角色属性匹配得丝毫不差,小地图导航也顺得很。Notion AI主管都夸它“性能提升、token消耗少了、错误率也低了”。但槽点也不少:独立测评机构VellumAI的数据显示,BrowseComp评分比4.6版本掉了4.4分,连GPT-5.4 Pro都打不过;长上下文检索准确率更是从78.3%暴跌到32.2%,被扒出是“用一堆干扰项糊弄模型”。
更离谱的是幻觉问题。有用户发现模型会假装搜索,明明没调用搜索工具,却硬说“已搜索但没找到”;聊代码的时候,还编出个不存在的“产品负责人Anton”,理由竟然是“代码里有德语单词,Anton在德国常见”。新出的“按问题复杂度分配计算资源”功能也成了摆设,处理地缘政治分析、物理计算这类复杂任务时,动不动就进入“低功耗模式”,关联分析能力直线下降,得用户催好几遍才肯挖细节。
面对质疑,Anthropic解释说部分性能下降是“有意调整”,但用户可不买账,觉得这是“为了安全对齐牺牲上下文忠实度”。雪上加霜的是,新版用了新的tokenizer,相同文本的token数多了0-35%,订阅价格还涨了50%,大家纷纷吐槽“根本不把普通用户当回事”。
说到底,Claude Opus 4.7在工程工具这块确实亮眼,编程、处理文档都挺顺手。但风格变得跟其他AI没两样,核心能力不升反降,还让人没了信任感,那些靠它“人味”和深度推理的用户自然要喊“退坑”。这场争议也暴露了AI迭代的老大难问题——怎么在“能力提升”和“用户偏好”之间找到平衡,真没那么简单。
闻喜配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯




